It's 9:00 on a Monday morning. You're sitting at your desk savoring that precious first cup of coffee and looking forward to finally finishing that rendering routine when your boss knocks on your door. She says, "I have a little job for you." It seems the product manager was wrong: customers do want to convert their old flat-text input files into XML. Oh, and the three people who actually bought Version 6.1 of the product want to merge parameters from the database as well. Now you've got to take care of it--by the end of the day.
Little data crunching jobs like this come up every day in our business. They aren't glamorous, but knowing how to do them with the least amount of effort can be crucial to a project's success or failure.
Fifteen years ago, most data crunching problems could be handled using classic Unix command line tools, which are designed to process streams of text one line at a time. Today, however, data is more often marked up in some dialect of XML or stored in a relational database. The bad news is that grep, cut, and sed can't handle such data directly. The good news is that newer tools can, and the same data crunching techniques that worked in 1975 can be applied today.
This article looks at what those tools and techniques are, and how they can make you more productive. We start with a simple problem: how to parse a text file.
Extracting Data from Text
The first step in solving any data-crunching problem is to get a fresh cup of coffee. The second is to figure out what your input looks like and what you're supposed to produce from it. In this case, the input consists of parameter files with a .par extension, each of which looks like this:

Each line is a single setting. Its name is at the start of the line and its value or values are inside parentheses (separated by commas if necessary).
The output should look like this:
Most data-crunching problems can be broken down into three steps: reading the input data, transforming it, and writing the results. wc *.par tells us that the largest input file we have to deal with is only 217 lines long, so the easiest thing to do is read each one into an array of strings for further processing. We'll then parse those lines, transform the data into XML, and write that XML to the output file. In Python, this is:

Separating input, processing, and output like this has two benefits: it makes debugging easier and allows us to reuse the input and output code in other situations. In this case the input and output are simple enough that we're not likely to recycle them elsewhere, but it's still a good idea to train yourself to write data crunchers this way. If nothing else, it'll make it easier for the next person to read.
All right, let's begin by separating the variable name from its parameters, then separate the parameters from each other. Hmm . . . can there ever be spaces between the variable name and the start of the parameter list? grep can tell us:
![]()
Another quick check shows that while parameter values are usually separated by a comma and a space--sometimes there's only a comma.
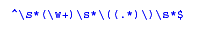
This sounds like a job for regular expressions, which are the power tools of text processing. Most modern programming languages have a regular expression (RE) library. A few, like Perl and Ruby, have even made it part of the language. A RE is just a pattern that can match a piece of text. These patterns can express complex rules in a compact way. When a match is found, the pattern remembers which bits of text lined up with which bits of the pattern, so that the programmer can extract substrings of interest.
The bad news is that RE notation is one of the most cryptic notations programmers have ever created (and that says a lot). When mathematicians want to express a new idea, they can just create some new symbols on a whiteboard. Programmers, on the other hand, are restricted to the punctuation on a standard keyboard. As a result, many symbols can have two or three meanings in a RE, depending on context. What's worse is that those meanings can be slightly different in other languages. Therefore, you may have to read someone else's RE carefully to understand what it does.
For example, here's a RE that matches a variable name, some optional spaces, an opening parenthesis, some text, and a closing parenthesis:
Let's decipher it in pieces:
- The ^ is called an "anchor". Rather than matching any characters, it matches the start of the line. Similarly, the $ anchor at the end of the RE matches the end of the line.
- The escape sequence \s matches any whitespace characters, such as blank, tab, newline, or carriage return. The * following it means "zero or more," so together, \s* matches zero or more whitespace characters. This allows the pattern to handle cases in which the variable name in the input line is indented.
- \w matches against "word" characters (which to programmers means alphanumeric plus underscore). Putting + after it means "one or more," (i.e., the variable name has to be at least one character long). Putting parentheses around the whole sub-expression signals that we want whatever matched this part of the pattern to be recorded for later use.
- We then have another \s*, to allow spaces between the variable's name and the first parenthesis.
- The parenthesis itself has to be escaped as \(, since a parenthesis on its own means "Remember whatever matched this part of the pattern." We also have to escape the closing parenthesis as \).
- Finally, . on its own matches any single character, so (.*) means, "Matches zero or more characters, and remember them."
Simple, right? OK, it isn't. As I said earlier, the notation can be cryptic. But once you've mastered REs, they can make complex jobs easier. For example, here's the first part of our transform function:

The first line inside the loop tries to match the regular expression against the line of text. If it doesn't match, the program reports an error. If it does, the program grabs whatever text matched the parenthesized groups inside the RE. For example, if the line is:
then var will be assigned "mouse," and params will be assigned "'fast', chord'."
To get the individual parameters, we use another pattern that matches the separators--in this case, a comma followed by zero or more spaces, or ,\s*. Adding this to the code above gives us:
Creating XML
Each line of input is independent of the others, so we could create XML simply by printing strings. However, experience has taught me that it's usually a bad idea to treat structured data as strings--sooner or later, the structure is actually needed and the crunching code has to be rewritten.
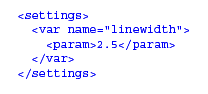
The standard way to work with XML in a program is to use the Document Object Model (DOM). As defined by the World Wide Web Consortium, DOM is a cross-language set of objects that represent elements, attributes, text, processing instructions, and all the other weird and wonderful things that can appear in XML. For example, the XML document:
corresponds to the object tree shown in Figure 1. Note that:
- The root of the tree must be a Document object, whose single child is the root element of the document.
- All of the text--including the whitespace between elements--is stored.
There are several DOM implementations in Python, such as minidom (which is part of the standard library), and packages, like Fredrik Lundh's ElementTree, that have similar features, but more Pythonic interfaces. There are also special-purpose tools, like XSLT, which are custom-built for working with XML. In practice, though, I've usually found these special-purpose tools to be more trouble than they are worth. Especially since most don't include features like regular expressions and database libraries that my crunching programs need.
For our purposes, minidom will do fine. What we have is a list, each of whose elements is a variable name and a (possibly empty) list of parameters. What we want is some XML. Let's start by creating the document and its root settings element:
For each entry in data, we need to add a new var element to the settings:
def process(data);
for (var, params) in data:
varNode = doc.createElement('var')
varNode.setAttribute('name',var)
root.appendChild(varNode)
. . .
return doc
Similarly, for each parameter, we need to add a param element to the var element. We must also add a text node to the param element to store the parameter's value:
Great, except that when this document is converted into text for output, the result is:
There are no newlines or indentation to make it easy for human beings to read. We could easily insert them by adding text nodes in the right places, but there's no point since these files are only going to be read by other programs. In my next column, I'll explain how to merge your new XML data with a database.
Figure 1.
User Comments
Greg,<br/><br/>Great article, I look forward to part 2! I do have one question, where is Figure 1?<br/><br/>Thanks,<br/><br/>John Leather
Greg,<br/><br/>Great article, I look forward to part 2! I do have one question, where is Figure 1?<br/><br/>Thanks,<br/><br/>John Leather
Pages