Bisection and Beyond
When you search through an ordered list, like a dictionary or phone book, you're probably using the bisection technique to find the information you need rather than starting at the beginning of the book and turning the pages one at a time. In the world of testing, bisection can make your testing much more efficient. In this week's column, Danny Faught describes the basic bisection technique and how to modify it in order to better respond to the real world.
Let's say I'm testing an integer input field. I input 0 and the test passes, and then I input 1,000,000 and the software crashes. Before I file a bug report, I want to find where the transition point is between a passing test and a crash. Just like it speeds up a search through a dictionary, bisection (also known as a "binary search") can help to find the number we're looking for.
Bisection Basics
Here's how bisection works: Keep track of the largest number that hasn't failed the test and the smallest number that failed. In our example, that's 0 and 1000000, respectively. Then try the number halfway between the two, which is 500,000 in this case. (We can find this middle point by averaging the two end points.) If the test fails, then we can make a hypothesis that all inputs between 500,000 and 1,000,000 will cause a crash. Our new end points are 0 and 500,000; we've eliminated half of our search space.
Here's a hypothetical example of a testing session where we find our needle in a haystack--a single value out of 1,000,001 that represents the lowest number that results in a failure. Each row is a test case, showing our two endpoints and the average of the endpoints (truncating fractional values) that become the input for that test. The result of each test determines how the endpoints will be adjusted for the test on the next row. It doesn't matter what kind of software you're testing or what your test is, the approach will work for any integer input.
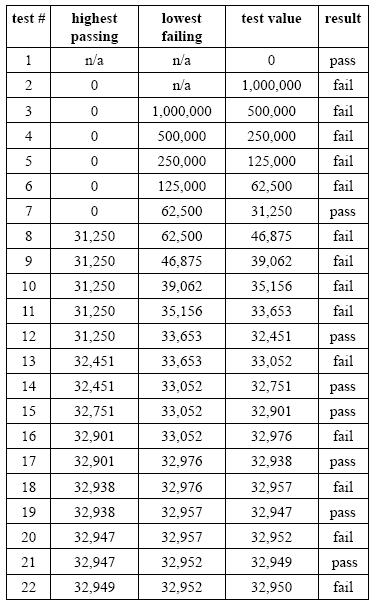 |
| Table 1: A hypothetical example of a testing session using the bisection technique. |
After twenty-two tests, we know that the test passed at 32,949 and failed at 32,950. We now have much greater detail to include in the bug report.
By the way, if you know your powers of two, you might recognize that my hypothetical failure point of 32,950 is close to 215, or 32,768. While I do often find failure points at powers of two, just as often there's no obvious reason why the software fails at that particular point.
Moving Targets
The real world can throw you some curve balls that you have to hit. One that can cause massive confusion is a moving failure point. As you're trying test values, you may see the same input passing your test on one occasion but failing it on another. This sometimes happens within the same testing session, but most often when you restart the application or run it on a different computer, especially when hours or days have passed since your last test.
In our example above, I recommend adding two tests: Try 32,949 and 32,950 again to see if the failure point is moving. This also helps to verify that you didn't make an error recording the results of a previous test. It's easy to get lost in the details and make a mistake. Even if you don't immediately see a moving boundary, there still could be conditions that cause it to move, so keep an open mind when you help the developer further isolate the cause of the bug.
Cheating
Bisection works most efficiently when your next test input is exactly halfway between your two endpoints (assuming you don't have any clues about where the failure may lie). But don't feel obligated to be so exact if you're testing manually. If I were testing manually in our example above, once I got to 125,000, I probably would have chosen rounder numbers that I could calculate easily in my head like 60,000, 30,000, 45,000, etc. This approach usually requires a few extra tests to find the failure point, but if your tests run quickly, this can increase your productivity because it makes the math much easier.
There are other reasons why you might use a different method of choosing your next input. You may have a hunch about where the failure lies, such as a power of two like 32,768. Follow these hunches. As long as your next input is somewhere between your two endpoints, the basic algorithm will still work.
In our example, I chose 1,000,000 as the second input in order to keep the table short. I usually would use a much larger number like 10100. I know that the failure point is probably much closer to 0 than 10100, so I start my search by going down more of a logarithmic scale like 1050, 1025, etc. (Note that I'm bisecting on the exponents rather the value itself.) I do this until I cross the boundary, then I go back to a linear scale.
Multiple Failure Points
Pat yourself on the back when you find your first boundary, but know that you're not done yet! You can usually find at least two different failures in the same input field, for example, a non-fatal error in one input range and a crash in a higher range. You already may have tripped over a different type of failure while you were isolating one of them. When that happens, you have to decide whether to find the boundary between a passing test and the first failure or the boundary between two failures. Once you've done that, go back and find the other boundaries.
If serendipity didn't bring you more than one failure mode, try much larger inputs than anything you've used before. I usually won't give up until it simply takes too long to generate and process the input to justify further testing.
Where to Use It
Besides integers, you can use the bisection approach with any other input that has a size of some sort, such as floating point numbers, string lengths, and file lengths.
Keep in mind that you'll save your sanity if you keep careful notes while you're isolating a failure using bisection. It goes so quickly that it's easy to lose track of where you are.
