But there’s still a lot to do to move acceptance of the DVCS beyond early adopters. What else can be done to help developers in their daily version control experience?
Diffing and merging
Diff and merge tools are two version control features that developers use on a daily basis, but which haven’t received a lot of attention in years. Yes, there are more and better colored interfaces today than ten years ago, but the underlying algorithms are all text based, so they can work in a language-agnostic way. Evolution seems to have skipped this field.
Today I’ll be talking about some of the trends in the next generation of diff and merge tools and how they can impact a developer’s day to day activities.
Refactoring is the key
Let me focus on one of the best practices widely adopted by developers, independent of their programming language or the industry they’re working in: refactoring. Refactoring code applies a simple set of rules and actions to it, transforming its format without altering its behavior. There are many reasons to refactor, with improving readability one of the most important.
What does refactoring have to do with version control? If we apply it at the file level (you know, a Java class lives in a file named after the class), ) it is quite clear that proper tracking of moves and renames is key to supporting simple things like renaming a class or locating it in a different module or package. The same applies for packages and directory trees . As simple as it sounds, good support for moved and renamed files and directories has been around for only a few years (unless you were using one of the high-end commercial SCMs), and was totally out of the scope of some of the widely used open source version control systems before the DVCS era.
But today I’m thinking about operations performed inside a single file: you move a private method down in your class (following what you learned on Clean Code, for instance), you diff it with the previous version of your file, and the typical diff tool identifies two separate changes: one block added and another block removed. There’s no automated way to tell it’s really the same code.
The following picture shows a similar example: a method has been moved up and detected as a “delete-add” pair of changes.
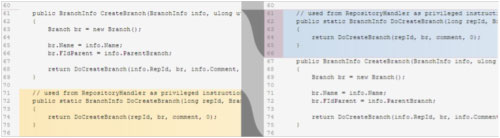
What if the diff tool was able to find that it’s really a single block of code has been moved?
The result would be something like the following, where the developer is informed about the “move operation”:
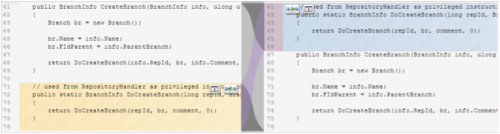
The former implementation is based on a modified “Levenshtein distance” algorithm and, as such, is language agnostic, so it can only be considered as an initial step towards the goals I mentioned above.
Refactoring can be harder
It is not unusual for developers to move methods around (and perhaps modify them a bit, as well) in a way that even an advanced text based algorithm would have big trouble figuring out the right matches. But as tough as it sounds for a “text based” diff system, it would be trivial for a “code based” diff: a tool that actually parsed the file, locating its methods, properties, members, etc., and then used them as “units of change” It would be straightforward to figure out if heavy modifications to a file were really just a shuffling of its code units.
The idea is not new -- in fact, it’s a typical question developers ask when they’re trained on a new version control system with better merge support: “hey, are you able to deal with C# or Java code specifically?”. In that sense, delivering a new generation of SCM able to handle diffs and merge conflicts based on “understanding” the underlying code would be simply “meeting customer expectations”.
Note: the Eclipse IDE is already able to display an outline of the diffs between files showing which methods have been modified, added and so on.
Displaying a language-aware diff
Once the code has been correctly parsed, and the “code unit” differences have been calculated (not a trivial operation depending on the level of depth you want to achieve), the next step is to render the “language-aware” differences correctly.
My opinion is that we’ll end up with “combined views” where some sort of class/method layout will be combined with a traditional “text-based” diff, so that the developer can choose which view he wants to focus on. (This reminds me the UML class diagrams embedded in some development tools: they’re good to some extent, especially in communicating the “big picture”. But in the end, the code is the best “representation” (like in DSLs) of the inner workings of a class.)
A simple visual outline like the following could help indicate that one method has been modified, one renamed and moved, one deleted, and a new method added.
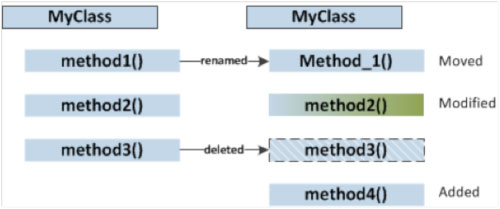
Remember that a change as simple as this one can be extremely hard to follow with a conventional diff tool nowadays, if the code blocks are non-trivial (or not especially short).
Then the “method2” differences could be easily expanded and most likely displayed in conventional “text diff” format:

Time to merge
It is clear that diff tools can greatly benefit from “code-aware” technology, but the real benefit will be during “merge time”. Merging is more and more common these days, thanks to better version control systems able to deal with an unlimited number of branches and able to correctly handle merge tracking. But when the problem is at the “file level”, after the candidates have been correctly identified, you’re still left with your conventional 3-way merge.
One of the easiest things a “language-aware” merge can do is to transparently handle added code. Here’s a simple scenario to illustrate the idea: you add a method at the end of the file and another developer adds a different method at the end of the same file. A conventional merge tool will detect it as a conflict, since the same line of code has been modified by two contributors. Obviously, such a conflict could be automatically resolved by a “language-aware” merge tool without any risk of error.
Another simple example illustrates the power of this kind of merging. Let’s take a look at the following C# code:
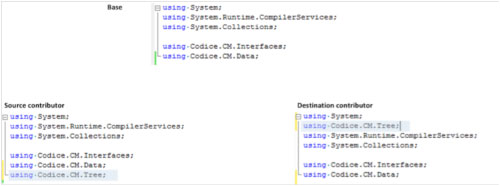
One developer modified the “using” area by introducing a new “using” statement. The second developer added the same “using” at a different location.
There’s no way to easily resolve this conflict with a conventional “text based” diff tool, but it would be trivial for a “language-aware” tool: it would go through the “using” statements, find a duplicate one, and keep just one of them -- all without user intervention.
While this exampleis perhaps too simple, it shows the wide range of benefits that “code parsing” brings to the SCM arena.
Shortcomings
Two shortcomings of code-aware tools immediately come to my mind:
- Parsing: right now code-agnostic diff and merge tools are able to deal with any text file. A “language-aware” system would have to develop support for each specific language, which is not rocket science but it is still much more expensive than developing a “one size fits all” solution.
- Broken code: what if your code doesn’t compile? Does it mean you can’t diff it or merge it? The solution here, in my opinion, is to be as pragmatic as possible and, as I mentioned, provide “multi-level” tools: you can perform some operations at the “outline level” and some others at the traditional “text level”. In case your code simply doesn’t compile, the merge tool will rely on its “text based” traditional technology to let you move forward.
Wrapping up
Developers around the world use version control systems on a daily basis and I think it is fair to state that most of the code developed nowadays is stored in a SCM system. Diffing is one of the common version control operations, and merging is becoming more and more common, too. Once the new DVCS generation “crosses the chasm” and goes mainstream, there will be time for further improvement. I strongly believe there’s a lot of work to do to improve merging and diffing. Small productivity gains focused on individual developers can result in huge overall speed ups and gains in industry productivity.