1. Introduction
In the current competitive Internet scenario, as the software products are expected to offer more and more complex functionality, expectations on higher reliability too goes hand-in-hand. Further, this is more critical in case of server software products. Needless to say, reliability of a server is a key factor both to the software developer and the customer, to make decisions, and hence a key factor for quality. The server software is expected to run without any failures for a continued period of time to support present business needs. In the e-commerce scenario where the server is expected to run round the clock catering to the customers throughout the world, spanning different time zones, there is no chance to reload or restart the server application. These requirements make the reliability testing more complex and critical.
This paper talks about "Software Reliability", the case of testing for reliability of server software, and highlight the challenges in planning, automation, execution, collection and interpretation of the data for determining reliability as well as some practical challenges/difficulties faced. It also talks about the relationship of reliability testing to other areas of testing such as performance and functionality.
2. Definition
Software reliability can be defined as the degree to which there is failure-free functioning of the software for a specified period of time or specified number of iterations/transactions, in a specific environment. Software reliability is an attribute and key factor in determining software quality.
Reliability of software describes the customer's expectation of satisfactory functioning of the software in terms that are meaningful to the customer. This description may be significantly different from the theoretical definition. The customer must tell the circumstances under which they will 'trust' the system that will be built.
The following are the key factors for reliability of the software:
- No or very few errors from repeated transactions
- Zero downtime
- Optimum utilization of hardware resources
- Less utilization of network resources
- Consistent performance and response time of the product for the repeated transactions for a specified time duration
In a typical Client-Server scenario where the server products are assumed to be up and running all the time, it may be ensured performance of serving numerous clients without any considerable response delays by consuming optimum amount of resources of the system such as memory, CPU...etc.
The power and efficiency of the hardware resources have been increasing tremendously over a period of time and the software should be designed to utilize all the resources optimally to provide maximum returns for the investment of the customer. At the same time the server application under test, should yield these resources to other critical applications that may run on the same hardware as necessary.
In today's Internet scenario the server software performing reliably on a system is not enough, the implications of the software on the network are also equally important. The software should be designed to work utilizing less of network resources, as there are many customers who still have low network bandwidth and may be running other applications on the same network. So, a software reliability testing should also include the impact of the software on the network.
What is important is, the customer needs or expectations are described in a quantifiable manner using the customer's terminology.
Some examples of reliability are:
The system will be considered sufficiently reliable if:
- 10 or fewer errors result from 1,00,000 repeated transactions
- It supports X transactions per second throughout the specified period of time (i.e., there is no degradation of performance because of reliability)
- The software optimizes hardware, software and net resources for repeated transactions
- There are no side effects after the repeated transactions
- The server software scales up with the number of processors for repeated transactions (This implies that the future needs of the software can be met by increasing the system resources)
All participants in the development process need to be aware of these reliability issues and their priorities to the customer. If possible this awareness should come from direct contact with the customer during the requirements gathering phase. Ideally, reliability issues should be determined up front before design begins. The reason being, most of the reliability defects require design changes to fix them.
3. Planning and Executing Reliability tests
Test cases shall be designed to satisfy the operational requirements of the software and shall be run on the complete software. Depending on the form of the reliability requirement, either the 'time to failure' or the 'number of transactions to failure', or similar shall be recorded. When the software fails, the fault that led to the failure shall be filed into defect tracking system and notified to concerned software development team. Testing shall continue until sufficient measures are available to predict that the required level of reliability has been achieved. The software's reliability shall be measured using the records of the testing.
Testing can be done in two ways. On one hand, testing can be seen as a means of achieving reliability: here the objective is to probe the software for faults so that these can be removed and its reliability improved. Alternatively, testing can be seen as a means of gaining confidence that the software is sufficiently reliable for its intended purpose: here the objective is reliability evaluation. In reliability testing, defect density (normally represented in 3 sigma, 6 sigma quality levels) and critical factors are used to allocate important or most frequently used functions first and in proportion to their significance to the system. This way reliability testing would also exercise most of the functionality areas of the product during the test execution.
Reliability testing is coupled with the removal of faults and is typically implemented when the software is fully developed and in the system test phase. A new version of the software is built and another test iteration occurs. Failure intensity is tracked in order to guide the test process, and to determine feasibility of release of the software.
While planning the test cases for reliability, one needs to consider the various sub-systems failures and design the test cases. For example, in a server with two network interface cards, if one card fails the software should still continue to run with very less degradation on performance utilizing the other card.
Quite often mechanisms like tunable parameters and caching which are used to improve the performance of the product may have side effects impacting the reliability. These parameters need to be included in testing the reliability of the software.
The best results of reliability testing can be achieved by “setting up a task force” with developers, test engineers and designers, as defining the reliability requirements, reproducing the reliability defects are often very difficult. More over analyzing any reliability behavior requires continued effort collecting and analyzing the data by all the members of the task force.
The testing procedure executes the test cases in random order but, because of the allocation of test cases based on usage probability, test cases associated with events of greatest importance to the customer are likely to occur more often within the random selection.
Once the product meets minimum entry criterion, the reliability testing starts, different milestones are set to do a more effective testing on the product. These milestones depend on various parameters like, response time for a request, number of clients used, resource utilization and the test execution time. Let us take the example of Client-Server application again to explain what are these milestones. The parameters are represented using a graph as below:
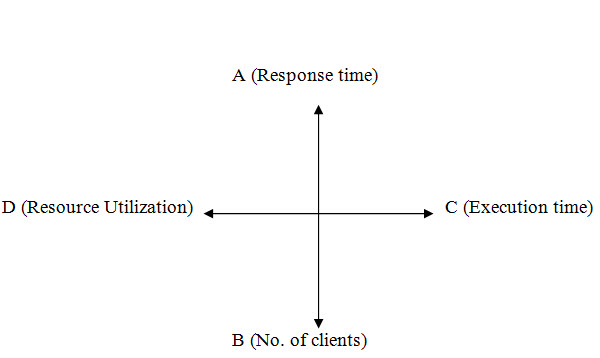
The A-axis represents the average response time for the client’s request, B-axis represents the number of clients used, C-axis represents the number of hours the test is executed and D-axis represents the resource utilization during the time period of the reliability test. In turn, the graph depicts four important aspects involved in reliability testing namely, A-axis for performance, B-axis for scalability, C-axis for reliability and D-axis the investment for reliability. According to the entry criterion for reliability testing, the server software should have a minimum response time consistently for specified number of hours and with specified number of clients. Milestones are set on this basis. For example, in the Client-Server scenario, a server product is running on a highend machine, which responds to all clients' requests with minimal response time. To start with, the first milestone would be to have a minimum number (say 25) of clients used to shoot requests against the server for a specific period of time (say 24 hours). Once the server is able to handle this load with minimum response time, next milestone (say 50 clients) is set and executed. So, the number of clients keeps increasing until a specific criterion is met or the server fails to handle the situation. This kind of testing also helps in analyzing the performance of the product. For example, we can find out the response time of a request in proportion to the number of clients used. The table below illustrates an example with different milestones set for a reliability test:

The test execution process for reliability is repetitive and time consuming; the best approach for testing reliability would be automating the test cases. Without automation the desired results of the reliability testing cannot be achieved at all. The automation would reduce the test engineer's intervention with the product to a great extent, saves a lot of time, since there is less intervention, there will be less human errors and finally, the test can be executed repetitively. Automating the test cases for reliability is not a simple task. There are many requirements for automating the test cases:
- Configuration parameters, which are not hard coded
- Test case/suite expandability
- Reuse of code for different types of testing
- Coding standards and modularization
- Selective and Random execution of test cases
- Remote execution of test cases
- Reporting scheme
And also, if the test stopped in between for some reason, the test suite should report the reason for failure or it should resume the test execution by ignoring it. These are some essential requirements for a test suite.
4. Collecting Reliability Data and Interpreting
The results are collected and a report is generated which helps in predicting when the software will attain the desired reliability level. It can be used to determine whether to continue to do reliability testing. It can also be used to demonstrate the impact on reliability, of a decision to deliver the software on an arbitrary (or early) date. The graph below illustrates a typical reliability curve. It plots failure intensity over the test interval.
The failure intensity figures are obtained from the results during testing. Test execution time represents iterative tests executed. It is assumed that following each test iteration, critical faults are fixed and a new version of the software is used for the next test iteration. Failure intensity drops and the curve approaches the pre-defined stable minimum criterion.
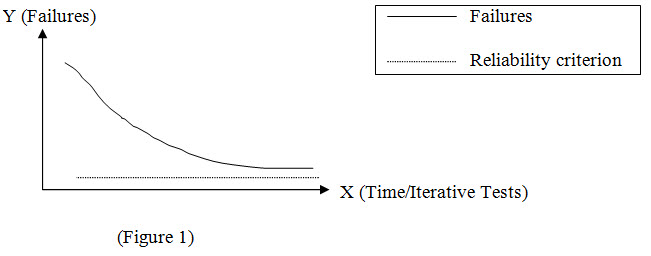
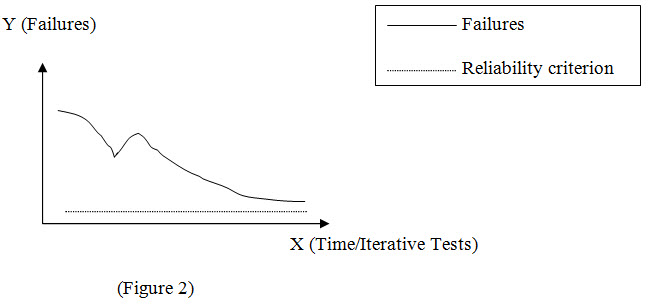
Figure 2 illustrates when the process for fixing detected errors is not under control, or a major shift in design may have occurred as a result of failures detected.
Failure intensity drops, spikes, and then makes a gradual decline. The spike shows that while fixing the known errors, some new errors were introduced. This graph identifies two potential problems. The process for fixing errors may be inadequate and there may be weak areas in the development process itself.
Apart from analyzing functionality failures, resource utilization by the software should also be given importance. A tool should keep running in the background which keeps track of resource utilization like, Memory, CPU…etc. The tool should log the report at regular intervals during the test. A sample log file is shown below:
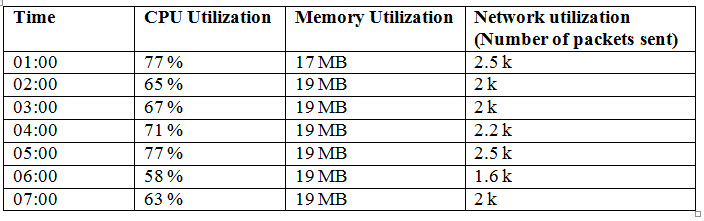
The CPU and Memory utilization must be consistent through out the test execution, if they keep increasing, other applications on the machine can get affected, the machine may even run out of memory, hang or crash, in which case the machine needs to be restarted. Memory buildup problems are common among most of the server software. These kinds of problems require lot of time and effort to get resolved.
5. Conclusion
In any enterprise scenario, the software product is assumed to be up and running with minimal failures. Testing for Software Reliability plays a vital role in ensuring the product meets the customer's expectations. Reliability testing needs proper planning and execution. Automation would help in executing reliability tests. Reliability test results would help in deciding whether the software has met the desired quality and help make a good decision to release.
