The Scenario
You work on a software team, and someone decides that a continuous build would be a good idea. Someone should give that person a raise! But, who is going to put this thing together? Software developers typically just want to write code, not build information systems. The IT department typically doesn’t know enough about the software development and testing process to configure such a beast. This is something for your project’s toolsmith—a role I gladly take on in engineering teams.
The following is a real-world case study of the build system at my workplace. I hope it will ease your transition into the wonderful world of continuous builds with Hudson.
The Evolution of Our Build Server
When we began continuous builds about seven years ago, I built a homegrown server (best bang for the buck at the time) to handle the work. Our build job consisted of compiling Java code and creating a war file for our testers to deploy. This ran in a few minutes, and life was good. The testers no longer needed to build code manually on their workstations, saving them a headache and making them more efficient. The build server emailed the committers to tell them if the build passed or not. Since this was just a compile, it passed 99.9 percent of the time.
This was before we had a suite of JUnit tests to run. We had a JUnit here and there but nothing that consisted of a full suite of tests. Our boss at the time, Mike Cohn, set out to change that. We started in on a test-first methodology, created a top-level test suite, and added that to the build. Our build time was starting to increase, and the successful build percentage started to fall.
Our whiz-bang tester, Lisa Crispin, was using a web application testing tool from a company called Canoo. The framework is an open source project named WebTest. When Lisa wanted the WebTest test integrated into the build, I was able to add it and write a plug-in for our build system at the time, CruiseControl, to capture the results. This was the beginning of the end of that homegrown server. The build time was up to around ten minutes, even with a watered-down list of tests to run. We created a build to run all of the tests at night, as this now took almost an hour. Our build server also crashed. We were feeling some pain for the first time.
Build Servers Two and Three
Again, I built a homegrown server using 2 AMD 2600MP CPUs. We called this server “Build 1.” Our regular continuous build times crept up as we added JUnit tests, and we hit the ten-minute mark again. We made an internal goal to keep the build down to seven minutes, but to accomplish this we had to buy another server. This one we called “Build 2.” Build 2 got the continuous build down to seven minutes, and we used Build 1 for the “nightly” build, which, at this point, ran whenever it could after it saw a check-in.
Failure after Failure
We beat the crap out of these servers. During the workday, they ran nonstop. Builds were both IO and CPU intensive, so these servers got extremely hot and components (typically the drives) failed. Each time they would fail, we would feel it. Not only did we have to recover the hardware, but also our code started to degrade as regressions were not caught quickly. It took even more time to find the bugs, as they were “stacked” and it was not clear which check-in caused the failure. Time is critical when you are doing two-week iterations, so these failures usually caused our releases to slip. However, this is something we had to live with as money was always allocated to other functions in the company and not so much to build servers.
Migration to Hudson
One thing I could never get to work in CruiseControl was the “distributed” build. This seemed to be critical if we wanted to get the build time down. When our build time got out of hand again, I started looking at other build systems, including Hudson. I had played with Hudson before and liked it, but I hadn’t had the time to convert our build to it.
Every six months or so, we get what we call a “refactoring” or engineering sprint, where we upgrade tools and libraries and refactor really bad code. Leading up to this sprint, I installed Hudson on my Linux workstation and started to play with it. We also had a new coding project with its own source tree to deploy that needed its own build but had no home. I sent the team some eye candy screenshots of the new project in Hudson and it didn’t take long before they were sold. This would be an official project for the engineering sprint.
During the engineering sprint, we successfully converted Build 1 and Build 2 into Hudson build slaves and left my Linux box as the Hudson master until we purchased a Dell PE 2850—the first real server in our build farm.
Hudson Is Too Good
Now that we had Hudson and everyone liked it, requests started coming in. First, Lisa wanted the Fitnesse tests fully integrated. We had a somewhat cheesy way of kicking off the Fitnesse tests, but not a good way to get the results. She polled her community and found a plug-in that someone wrote to present Fitnesse tests into Hudson. At the same time, we upgraded Fitnesse, which changed the format of the test results. We used someone else’s XSL style sheet to convert the results back to the previous format. But, now that Fitnesse tests could be integrated into the build, the system started to get overloaded yet again.
The Obvious Way to Configure a Hudson Build System
Our tests did what you might expect and had to use external servers outside Hudson’s control. For example, the Canoo WebTest tests had to run against a web application server with the latest code deployed. Though we used a single web application server and a single suite of WebTest scripts, this would take hours to run. The Fitnesse test was a similar process, with a single external Fitnesse server outside of Hudson’s control. Parallelizing the test became necessary in order to keep the test-results feedback loop short. However, this presented a problem. The tests were never meant to run in parallel. Refactoring the tests to work in this fashion didn’t seem like a good idea. They worked as they were, and rewriting would invalidate them—not to mention that it would simply be a lot of work. Another problem was that we would need more backend external servers to run the web application and to run Fitnesse.
The solution that worked best—I like to call it the “Obvious Way to Configure a Hudson Build System, but We Don’t Do It That Way for Some Strange Reason”—was to create a generic slave that had all of the software needed to run any test without hitting an external server. This meant that instead of the build slave running a WebTest test against an external server, it would start up its own web application server and run the tests against localhost. This worked well. Creating a new build slave was simple—the key was to have all the tools installed the same way, with the same usernames and passwords.
Victims of Our Own Success
This method worked too well. The testers started splitting up their test suites and were creating new build jobs left and right, mainly because it was so simple. They didn’t have to deal with hostname issues and whatnot. They simply had to create the new job from an existing Hudson job and change whatever they needed in order to run a different set of tests. When the job ran, it did not care what else was running because it was running in its own separate environment.
The build environment consisted of the Dell PE 2850 as the Hudson Master and Build 1, Build 2, and my old Linux workstation as build slaves. That workstation was working so hard that its big fans would turn up to full speed and make a ruckus by my desk. I eventually moved it to the server room and got a new Linux workstation. The problem was that there weren’t enough build slaves to handle the load and builds were getting queued up. When I sent a screen shot of Hudson’s home page to my boss, four builds were running and seven jobs were queued for a place to run. Our feedback loop was long.
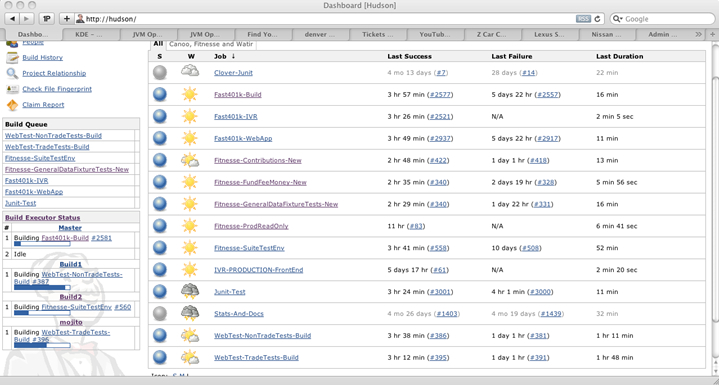
If you checked in some code to fix a WebTest test before lunch, you would be lucky to find out whether it had fixed the problem by the time you headed home. If you checked in after lunch, you’d wait until the next day for results. Something had to happen.
In the second part of this article, Virtual Hudson Build System: The Rest of The Story, I will discuss the solution we implemented to solve our long feedback loop problem.
