Kathy Iberle writes that when working on a project, you should take a systems view, which allows you to see the whole development system at once. When you put on your “systems view” glasses, you’ll see that you need to deal with the whole system, not just a single team’s part of it.
The very first time I used anything resembling an agile method was in the early 1990s. Our team of ten decided to attempt staged delivery on our next medical instrument project. We were motivated not by changing requirements (which were pretty rare), or a need for speed, but by a desire for higher quality and predictability. We thought the “smaller bites” of staged delivery would encourage adequate time for design while making it easier to predict what we could finish by the next trade show.
Staged delivery breaks the features into several groups and builds each group one at a time. This was a radical change from waterfall, but it wasn’t anywhere near today’s Scrum or XP. We didn’t have standup meetings, the stages were different lengths, the product was not shippable until close to the end, we didn’t accept new feature requests in each stage, and we kept right on writing all our usual documentation. Our “continuous integration” consisted of simply building the software from source code once a day.
Despite all these missing pieces, our staged delivery was a resounding success. There was adequate time for design, and we accurately predicted the true end date about halfway through the eighteen-month project. On our previous projects, we didn’t have a clue about the end date until the project was more than three-quarters finished. The upper management was very impressed, and staged delivery was adopted by other groups in that organization over the next couple of years.
In my next workplace, waterfall still reigned supreme—until 1999 and the “dotcom” boom. Waterfall simply couldn’t cope with this new, fast-moving market. We explored adaptive methods and evolutionary delivery and XP, trying out various combinations on our many short projects. I was puzzled to find that according to the books I was reading, our staged delivery at my last job years before shouldn’t have worked. We had left out practices that were labeled as absolutely necessary—yet I’d seen very positive results. I couldn’t explain this. Were we just lucky? As time went by, I grew more and more dissatisfied with the explanations of why agile worked, not to mention the ever-growing lists of necessary practices. I watched teams adopt all the practices and still struggle, and I couldn’t explain that, either.
In 2009, I was introduced to a different way to look at the flow of work in a project, one borrowed from mechanical engineering and known as “Second-Generation Lean." Suddenly, a light went on. This view explained why our staged delivery had worked! Not only that, but I could also see why some of the other agile projects weren’t working—and what could be done to fix them. It was like getting my first pair of glasses, when I saw individual leaves on the trees across the street instead of a green, fuzzy blur.
So what are these magic glasses? Start by taking a systems view: seeing the whole development system at once.
Imagine your development organization as a machine turning ideas into saleable stuff. The ideas move through a series of activities, with waiting areas, or queues, between them. I think of the work as little boxes or chunks moving through the activities and the queues. (See Figure 1.)
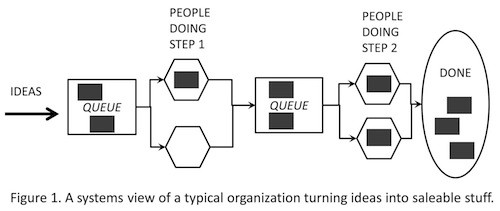
The behavior of this system—how fast those little boxes will get done—is described by a mathematical model known as queuing theory. Queuing theory predicts what will happen if you change the size of the boxes, the speed of the activities, or other factors. The math involves looking at a few graphs and equations, which didn’t bother me, so I kept reading. I learned that one of the most powerful factors is the batch size: the size of the chunk of work. A large batch size drives the cost up and the predictability down. The books go on about automotive engineering, but I stopped to think about software. What is the batch size in a waterfall project? Why, the largest possible batch size—every feature in the project! No wonder we were having problems. Any method that reduces the batch size by three-quarters or more will dramatically improve predictability and reduce cost as long as the batch consists of shippable code.
Finally, I had a good explanation of why the staged delivery project worked despite not using all the agile practices. Dividing an eighteen-month project into ten stages, each culminating in working code that passed system test, reduced our batch size by 90 percent. After five stages, we had enough information to predict our end date accurately and credibly. Had we divided the stage contents formally into user stories so we had something smaller to count, we would have been able to predict the end date even sooner. Working code really is the best measure of progress!
I soon discovered that the same pair of glasses shed new light on agile in large organizations. For instance, how do you handle a slow system test run by a different group? At one point, we had several Scrum and XP teams delivering into a single system test group. Each team could complete its design, coding, unit testing, and functional testing in a four-week sprint, but the system test of the full integrated product took an additional two to four weeks.
One of our team leads—let’s call him “Mike”—decided to count a user story as “done” when the story was delivered to the system test group. After all, his team had done everything that they were responsible for. After a couple of sprints, the team started estimating their capacity based on their velocity using this definition of “done.” A few sprints later, it was obvious that they were over-estimating what they could take on. Why? Their velocity measure didn’t take into account fixing the defects found in system test.
To fix this, Mike’s team considered not calling the story “done” until it had passed system test and was ready to ship. This necessitated a six-week sprint, with the final two weeks spent on system test. Measuring “done” this way would certainly improve the accuracy of the predictions, but most of the team would be idle during the last two weeks of the sprint because they didn’t do the system test themselves. That seemed silly.
Mike’s technical lead, Sally, suggested sticking with the current four-week sprint while adding some user stories to represent the time they would spend fixing defects in the previous sprints’ user stories. These stories went something like “As a user, I won’t encounter defects found in system test.” The product owners balked at funding stories with such a vague description, so this plan was abandoned.
Wearing the “systems view” glasses, we could see that we needed to deal with the whole system, not just a single team’s part of it. Mike’s team was not an island unto itself, and neither was system test. Essentially, Mike’s team (and the rest of the organization) was suffering from “fuzzy batches.” When exactly was the group of user stories for this sprint done?
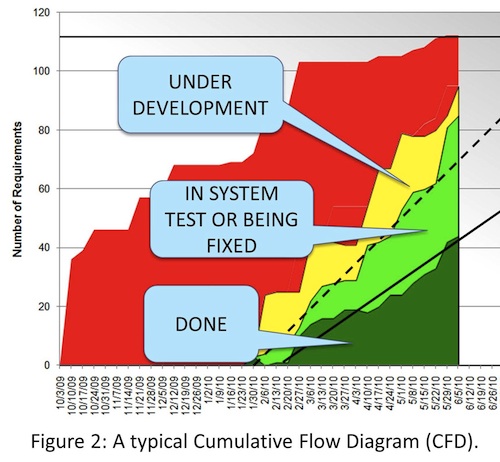
To answer this question, Mike and the other team leads needed to be able to “see” the progress of stories through the entire development system. The leads decided to view their system as four states: Backlog, Under Development, In System Test (which included bug fixing), and Done.
Queuing theory recommends graphing the date on which each batch enters each state. The system test group modified a requirements tracking tool to track four dates for each story:
- When a story was officially requested
- When the story was accepted into a sprint from the backlog
- When the story started system test
- When the story passed system test and was “done”
Using these dates, we plotted a Cumulative Flow Diagram (CFD) of all the stories. Figure 2 shows a typical CFD. A filter allows a team lead to exclude stories that don’t involve his or her team.
At this point, Mike could have his cake and eat it too. His team members continued running four-week sprints ending with the story being delivered to system test. They based their capacity estimates on how long it took to completely finish a story (the solid line in the CFD). The discussion with product owners at the start of the sprint now included not only what was in the backlog, but also acknowledging the stories from the previous sprint that were still in system test and might need further investment. Using a model with more states than simply “not started/started/done” allowed them to manage a more complex system.
The CFD provided another advantage to Mike and his fellow managers. They could see that stories were going into system test (the dotted line) at a rate faster than the stories were entering “done” (the solid line). Stories were accumulating in system test and fix. The project wasn’t as close to its schedule as the development progress suggested. Without the CFD, this would have been an ugly surprise later in the project.
Since this experience, when I hit a project management puzzle in agile, I put on my “systems glasses.” Drawing a systems diagram and applying the tools suggested by queuing theory brings the system into focus for me. When I can see it, it’s much easier to fix.

User Comments
If you're interested in learning more, see my suggested reading list at: http://www.kiberle.com/biblio.html
Kathy Iberle